

개발자공부일기
C++ Map vs Unordered_map: 해시 테이블과 트리의 차이 본문
1. 서론 - Hash와 Map의 개요
맵(Map)은 키(Key)와 값(Value) 쌍을 저장하는 연관 컨테이너를 말합니다.
한편 해시 테이블(Hash Table)은 키를 해시 함수로 변환하여 나온 해시값을 이용해 데이터를 배열의 특정 위치(버킷)에 저장하는 자료구조입니다.
사실 Map은 인터페이스 혹은 추상 자료구조이고, Hash Table은 그 구현 방식 중 하나입니다.
Map vs Unordered_map이라고 쓰여있긴 하지만, 더 정확하게는 이진 탐색 트리 vs 해시 테이블의 차이라고 볼 수 있습니다.
C++ 표준 라이브러리에서는 이러한 구조를 각각 `std::map`과 `std::unordered_map` 클래스로 제공합니다.
`std::map`은 이진 탐색 트리(레드-블랙 트리) 기반으로 동작하여 키를 자동 정렬해서 저장하고,
`std::unordered_map`은 해시 테이블을 이용해 저장하므로 키의 저장 순서가 유지되지 않습니다.
이러한 내부 구조 차이로 두 컨테이너는 성능 면에서 큰 차이를 보입니다.
본 포스트에서는 C++의 `map`과 `unordered_map`을 중심으로 각 자료구조의 동작 원리와 시간 복잡도 차이를 살펴보고, 상황에 따라 어떤 것을 선택하면 좋을지 정리하겠습니다.
레드-블랙 트리: 자동으로 균형을 잡아 트리 높이를 O(log n)으로 유지하는 이진 탐색 트리의 일종
2. 각각의 원리 설명 – 해시 테이블 vs. 트리 구조
해시 테이블 (std::unordered_map)의 내부 구조
unordered_map은 해시 테이블로 구현되어 있습니다. 새로운 키-값 쌍을 삽입할 때 키에 해시 함수(Hash Function)를 적용하여 해시 코드를 계산하고, 이를 내부 버킷(buckets) 배열의 특정 인덱스에 매핑합니다. 이렇게 해시값으로 결정된 위치에 해당 키-값을 저장하게 됩니다. 만약 다른 요소가 이미 해당 버킷에 들어있다면 해시 충돌(collision)이 발생한 것이므로, 데이터를 저장하기 위한 충돌 해결 과정이 필요합니다.
일반적인 충돌 해결 방법으로는 같은 해시값을 가진 요소들을 연결 리스트로 잇는 체이닝(chaining) 기법이나 빈 버켓을 찾아 재배치하는 개방 주소법(open addressing) 등이 있습니다. C++의 unordered_map 구현체들은 보통 체이닝 방식을 사용하여 충돌을 처리하며, 필요에 따라 버킷 배열 크기를 재조정(리해싱)하여 성능 저하를 막습니다.
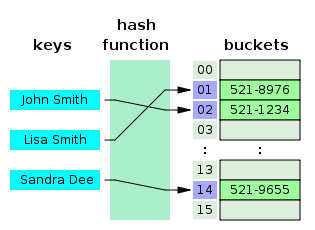
위와 같은 해시 테이블 구조 덕분에 키를 통해 배열 인덱스로 직접 접근하여 검색/삽입을 수행하므로 평균적으로 매우 빠른 접근 성능을 보입니다. 해시 테이블은 일반적으로 검색, 삽입, 삭제 연산을 평균 O(1)에 처리할 수 있어 대규모 데이터를 다룰 때 유리합니다. 다만 해시 함수의 품질에 따라 성능이 좌우되고, 충돌이 많아지는 최악의 경우에는 성능이 O(n)까지 떨어질 수 있다는 점도 기억해야 합니다. 또한 이러한 속도를 얻기 위해 해시 테이블은 내부적으로 추가 메모리(버킷 배열 공간 등)를 사용하게 됩니다.
트리 맵 (std::map)의 내부 구조
map은 내부적으로 정렬 이진 트리 구조로 구현되어 있으며, 구체적으로는 삽입/삭제 시 자동으로 균형을 잡아주는 레드-블랙 트리(Red-Black Tree) 알고리즘을 사용합니다. 새로운 요소를 삽입하면 키의 대소 비교를 통해 트리의 적절한 위치를 찾아 노드로 추가하며, 트리는 자동으로 균형을 유지해 높이를 최소화합니다. 이 과정에서 모든 키가 정렬된 순서대로 배치되기 때문에, 언제나 키 값의 오름차순으로 정렬된 상태가 보장됩니다. 예를 들어 map에 문자열 키를 삽입하면 사전순으로 정렬되어 저장되며, 이진 탐색 트리 구조를 이용해 키를 빠르게 탐색할 수 있습니다.
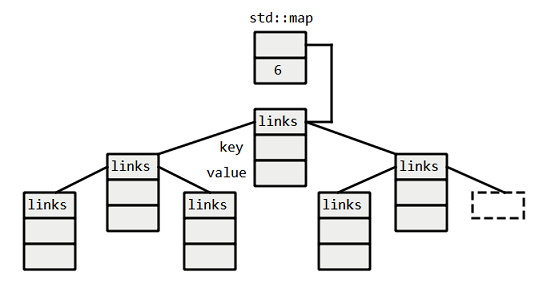
균형 이진 트리 특성상 std::map의 주요 연산들은 트리의 높이에 비례하는 O(log n)의 시간 복잡도를 가집니다. 검색을 위해서는 트리의 루트부터 키를 비교하며 내려가야 하고, 삽입/삭제 시에도 트리 구조를 유지하기 위한 연산이 필요하지만, 레드-블랙 트리는 이러한 연산이 항상 log n 단계 내에 완료되도록 보장합니다. 각 노드가 부모/자식 포인터를 포함하고 있어 unordered_map에 비해 원소 하나당 메모리 오버헤드는 약간 크지만, 항상 정렬된 상태로 순회(iteration)할 수 있다는 장점이 있습니다. 즉, map 컨테이너는 키 순서에 따라 순차적으로 데이터를 탐색하거나 범위 검색(lower_bound, upper_bound 등)을 수행하는 상황에 적합합니다.
3. 성능 비교 – 시간 복잡도
앞서 살펴본 내부 동작 원리 때문에 map과 unordered_map은 연산별 성능 특성이 다르게 나타납니다. 아래는 두 컨테이너의 주요 연산에 대한 시간 복잡도를 비교한 것입니다:
- 검색(find) / 삽입(insert) / 삭제(erase): std::map은 모든 연산이 트리 높이에 비례하여 O(log n) 걸리는 반면, std::unordered_map은 평균적으로 O(1)에 연산을 처리합니다. 다만 해시 테이블의 경우 앞서 언급했듯이 해시 충돌이 많을 때는 최악의 경우 O(n)까지 비용이 증가할 수 있습니다. 즉, unordered_map은 평균적으로 매우 빠르지만 최악의 경우에는 map보다 느려질 가능성이 있습니다.
- 전체 순회(iteration): 두 컨테이너 모두 원소 개수에 비례하여 O(n) 시간에 모든 요소를 순회할 수 있습니다. 하지만 순회 시 출력되는 키의 순서가 다릅니다. std::map은 키의 오름차순으로 정렬된 순서를 유지하며 순회하고, std::unordered_map은 저장 순서와 무관한 임의 순서로 요소를 반환합니다. 예를 들어 동일한 키-값들을 담고 있을 때 map은 키 값을 정렬하여 "apple, banana, cherry..."처럼 순회하지만, unordered_map은 "banana, apple, cherry..."처럼 예측하기 어려운 순서로 순회할 수 있습니다.
위 비교를 요약하면, 해시 테이블은 평균적으로 빠른 접근이 가능하지만(평균 O(1)) 최악의 경우 O(n)까지 비용이 증가 할 수 있고, 트리 맵은 키 정렬을 제공하면서도 안정적인 성능(O(log n))을 보장한다는 차이가 있습니다.
4. 사용 시 고려 사항 – 언제 Hash를 쓰고 언제 Map을 쓸까?
두 자료구조의 차이를 이해했다면, 실제 코딩 상황에서 어떤 경우에 unordered_map을 선택하고 어떤 경우에 map을 선택해야 하는지 판단할 수 있습니다. 선택 시 고려해야 할 사항들을 정리하면 다음과 같습니다:
- 데이터를 정렬된 상태로 유지해야 하는 경우: 키의 오름차순 정렬이나 범위 기반 탐색이 필요하다면 std::map을 사용하는 것이 유리합니다. 예를 들어 정렬된 순서로 데이터를 출력해야 하거나, [A, C] 범위에 속하는 키만 순회해야 하는 경우라면 map이 적합합니다. map은 항상 키를 정렬해 저장하므로 이러한 요구를 바로 충족하며, unordered_map처럼 별도로 정렬하는 추가 비용이 들지 않습니다.
- 최대한 빠른 조회 성능이 필요한 경우: 해시 테이블의 장점은 빠른 검색과 삽입입니다. 큰 규모의 데이터를 다루거나, 키를 통해 값 조회를 빈번하게 수행하는 상황(예: 캐싱, 빈도 카운팅 등)에서는 std::unordered_map이 평균적으로 더 나은 성능을 제공합니다. 특히 데이터 양이 많은 경우 O(log n)과 O(1)의 차이가 커지므로, 정렬이 불필요하다면 해시 테이블을 쓰는 편이 유리합니다. 실제로 주요 키-값 조회 테이블에서 map을 unordered_map으로 변경했을 때 조회 성능이 크게 향상되었다는 보고도 있습니다.
- 메모리 사용이나 오버헤드가 중요한 경우: unordered_map은 내부적으로 해시 버킷을 위한 커다란 배열을 할당하고 각 원소에 대한 추가 포인터를 유지하므로 map보다 메모리 사용량이 많아질 수 있습니다. 제한된 메모리 환경이나 메모리 효율이 중요한 프로그램이라면 map이 상대적으로 나은 선택이 될 수 있습니다. 또한 데이터 개수가 매우 적은 경우 두 컨테이너 간 성능 차이는 미미하며, 오히려 해시 연산 부하 때문에 map이 약간 더 빠르게 동작할 가능성도 있습니다. 작은 규모에서는 구현이 단순한 트리 구조의 오버헤드가 해시 테이블보다 작을 수 있기 때문입니다.
- 빈번한 삽입과 삭제가 이루어지는 경우: 데이터의 추가/제거가 매우 자주 발생하고 컨테이너의 상태가 계속 변한다면, 해시 테이블의 리해시(rehash)로 인한 부하를 고려해야 합니다. 많은 원소를 지속적으로 삽입/삭제하는 시나리오에서 해시 충돌 처리와 버킷 재할당 비용이 누적되면 unordered_map이 예상만큼 성능 이점을 발휘하지 못하는 경우도 있습니다. 이럴 때는 매 연산이 로그 시간에 일정하게 수행되는 std::map이 더 안정적인 성능을 제공할 수 있습니다. 즉, 데이터가 자주 수정되는 워크로드에서는 map이 유리할 수 있습니다.
아래 코드 예시는 unordered_map과 map을 사용하여 동일한 키-값을 삽입하고 순회하는 간단한 경우를 보여줍니다. 두 컨테이너의 사용법은 유사하지만, 출력 결과에서 키의 순서가 다름을 확인할 수 있습니다 (주석 참조):
#include <iostream>
#include <map>
#include <unordered_map>
using namespace std;
int main() {
unordered_map<string, int> umap;
umap["apple"] = 5; // "apple" 키를 해시하여 버킷에 저장 (평균 O(1) 삽입)
umap["banana"] = 3; // "banana" 키를 해시 테이블에 삽입
cout << "unordered_map: ";
for (auto& kv : umap) {
cout << kv.first << " ";
}
// 출력 예시: banana apple (저장 순서와 관계없는 임의 순서)
cout << endl;
map<string, int> omap;
omap["apple"] = 5; // "apple" 키를 이진 탐색 트리에 삽입 (O(log n) 삽입, 자동 정렬)
omap["banana"] = 3; // "banana" 키를 트리에 삽입
cout << "map: ";
for (auto& kv : omap) {
cout << kv.first << " ";
}
// 출력: apple banana (키 값이 정렬된 순서)
cout << endl;
}위 코드에서 보이듯 unordered_map은 삽입한 순서와 관계없이 "banana apple"처럼 순서가 일정하지 않은 반면, map은 "apple banana"처럼 항상 키가 정렬된 순서로 저장됩니다. 사용법은 비슷하지만 이러한 동작상의 차이를 고려하여 선택해야 합니다.
5. 정리 및 추천
정리하자면, std::unordered_map은 해시 테이블 기반의 구현으로 평균적으로 상수 시간(O(1))에 가까운 매우 빠른 검색 성능을 제공하지만, 데이터의 순서를 보장하지 않고 해시 충돌 시 성능 저하와 추가 메모리 소비 가능성이 있습니다. 반면 std::map은 균형 이진 탐색 트리 기반으로 동작하여 모든 연산이 O(log n)에 수행되고 키가 자동으로 정렬된 상태로 저장됩니다. 따라서 속도가 가장 중요하고 키 정렬이 필요 없는 경우에는 unordered_map을, 정렬된 순서의 유지나 메모리 관리가 중요할 경우에는 map을 선택하는 것이 바람직합니다. 특히 키의 크기가 크지 않고 조회가 매우 빈번한 경우 unordered_map이 유리하며, 반대로 트리에 비해 해시 테이블의 부가 비용이 부담되거나 순서가 중요할 때는 map이 더 나은 선택이 됩니다.
두 컨테이너 모두 장단점이 있으므로 사용 목적에 맞게 선택해야 합니다. 기본적으로는 삽입/검색의 평균 성능이 뛰어난 unordered_map을 고려하되, 정렬된 출력이나 특정 키 순서가 필요한 문제에서는 망설이지 말고 map을 사용하세요. 각 자료구조의 특성과 본인의 용도에 맞춰 올바른 컨테이너를 선택하면, C++에서 효율적이고 안정적인 데이터 관리를 할 수 있을 것입니다.
'CS지식 > 자료구조' 카테고리의 다른 글
| Red-Black Tree (0) | 2025.03.05 |
|---|---|
| B+ Tree (0) | 2025.03.04 |
| 이진트리, 이진 검색트리, 힙 (0) | 2025.03.03 |
| 그래프(Graph)와 트리(Tree) (0) | 2025.02.21 |
| Stack과 Queue (0) | 2025.02.17 |



